Warum KI-Projekte selten am Modell scheitern
Wenn ein KI-Vorhaben im Unternehmen stockt, fällt der Verdacht zuerst auf das Modell. „Vielleicht brauchen wir ein größeres LLM." In den meisten Projekten, die ich begleite, liegt das Problem aber woanders – im Drumherum, das selten auf Folien steht.
Der eigentliche Engpass ist die Umgebung
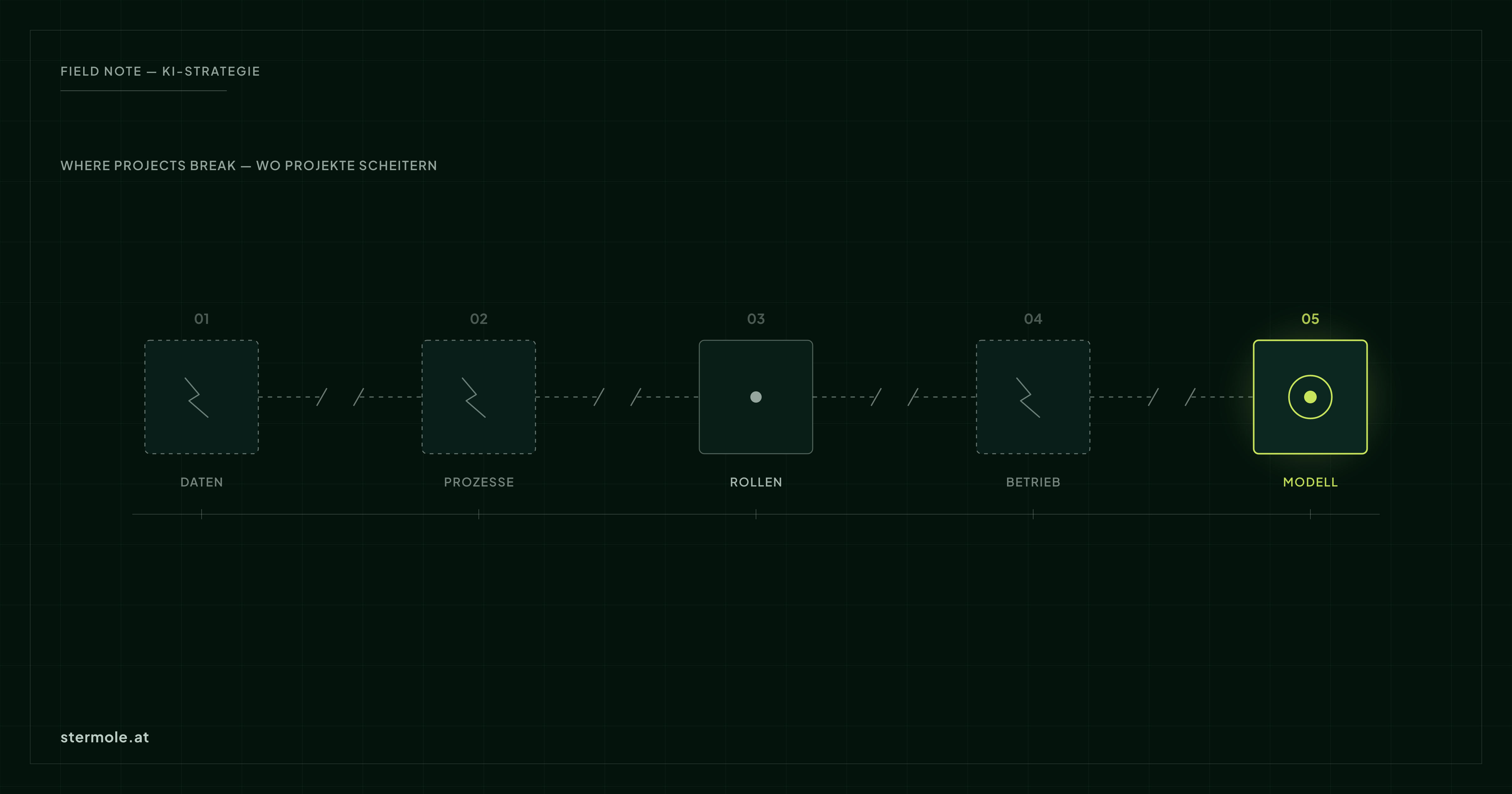
Moderne Modelle sind erstaunlich leistungsfähig. Was sie nicht mitbringen: saubere Daten, klare Prozesse, definierte Rollen und einen Betrieb, der die Lösung trägt. Genau dort entstehen die Reibungsverluste.
- Daten liegen verstreut, uneinheitlich und ohne klare Zugriffsregeln vor.
- Prozesse sind implizit – niemand kann sagen, wo die KI eigentlich andocken soll.
- Rollen sind unklar: Wer verantwortet Qualität, Datenschutz, Wartung?
- Betrieb wird vergessen: Ein Prototyp ist kein System, das im Alltag trägt.
Eine Demo beweist, dass etwas möglich ist. Ein System beweist, dass es verlässlich ist. Dazwischen liegt die eigentliche Arbeit.
Architektur vor Tool-Wahl
Die Frage „Welches Tool?" kommt fast immer zu früh. Sinnvoller ist die Reihenfolge:
- Nutzen klären – welches konkrete Problem lösen wir, für wen?
- Daten- und Rechtefluss festlegen – was darf wohin, unter welchen Regeln?
- Zielarchitektur skizzieren – lokal, EU-gehostet oder hybrid?
- Erst dann Tooling wählen – passend zur Architektur, nicht umgekehrt.
Wer diese Reihenfolge umdreht, baut Abhängigkeiten auf, die später teuer zu korrigieren sind.
Was das praktisch bedeutet
Ein realistischer Einstieg ist oft kein KI-Programm, sondern ein sauberer Workshop: Potenziale priorisieren, Risiken benennen, eine tragfähige Richtung festlegen. Das klingt unspektakulär – spart aber genau die Korrekturschleifen, die Projekte später ausbremsen.
KI wird wertvoll, wenn sie in die Realität passt: in vorhandene Prozesse, Systeme und Verantwortlichkeiten. Das Modell ist dabei selten die Hürde.