RAG richtig aufsetzen: vom Dokument zum verlässlichen Wissenssystem
Retrieval-Augmented Generation (RAG) ist zum Standardmuster geworden, wenn KI auf internes Wissen zugreifen soll: Statt das Modell neu zu trainieren, holt man relevante Inhalte zur Laufzeit dazu. Das Konzept ist simpel – die Qualität entscheidet sich im Detail.
Die Kette ist so stark wie ihr schwächstes Glied
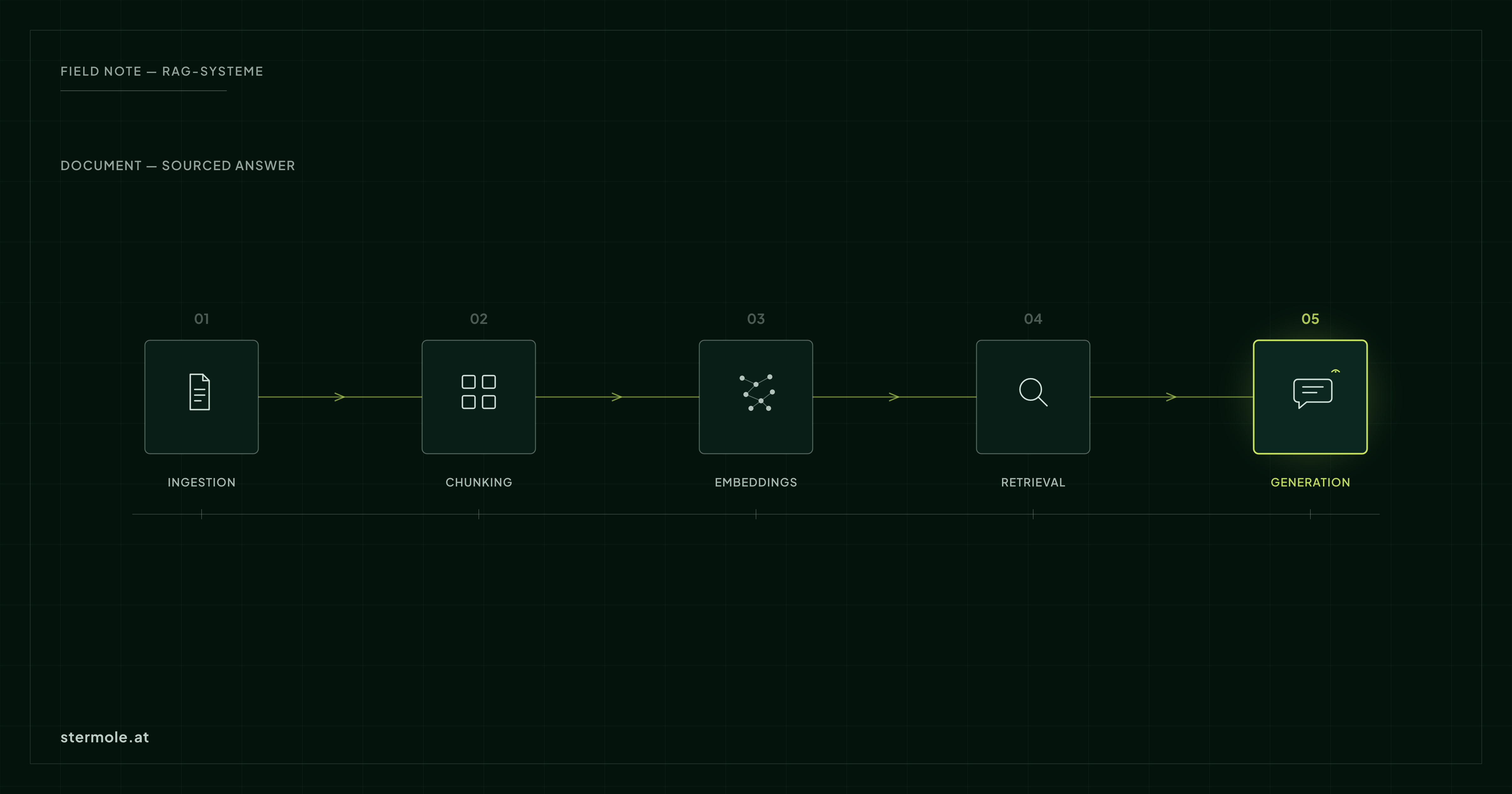
Ein RAG-System ist eine Pipeline. Jeder Schritt kann das Ergebnis ruinieren:
- Ingestion – Dokumente sauber einlesen (PDF, Office, Wiki). Schlechtes Parsing = schlechte Antworten.
- Chunking – sinnvolle Abschnitte statt willkürlicher Schnitte. Kontext muss erhalten bleiben.
- Embeddings – ein Modell, das zur Sprache und Domäne passt.
- Retrieval – relevante Treffer finden, oft hybrid (semantisch + Keyword).
- Generation – das LLM antwortet nur auf Basis der Treffer, mit Quellenangabe.
Die meisten „RAG-Halluzinationen" sind keine Modellfehler, sondern Retrieval-Fehler: Das Modell bekam schlicht den falschen Kontext.
Souveränität ist eine Architekturentscheidung
Gerade bei internem Wissen zählt Datenhoheit. Die gute Nachricht: RAG lässt sich vollständig souverän betreiben.
- Lokale oder EU-gehostete Modelle für Embeddings und Generation.
- Klare Rechte-Trennung – wer darf welche Dokumente überhaupt abrufen?
- Nachvollziehbarkeit – jede Antwort verweist auf ihre Quellen.
So bleibt sensibles Wissen unter Kontrolle, ohne auf Public-Cloud-KI angewiesen zu sein.
Pragmatischer Einstieg
Man muss nicht alles auf einmal bauen. Ein belastbarer erster Schritt:
- Einen klar abgegrenzten Wissensbereich wählen (z. B. Richtlinien, Verträge).
- Qualität messen: Beantwortet das System echte Fragen korrekt und mit Quelle?
- Erst dann ausweiten – wenn Nutzen und Kontrolle belegt sind.
RAG wird dann wertvoll, wenn es verlässlich ist – nicht, wenn es beeindruckend wirkt. Der Weg dahin führt über saubere Daten, klare Rechte und messbare Qualität.