Setting up RAG the right way: from document to reliable knowledge system
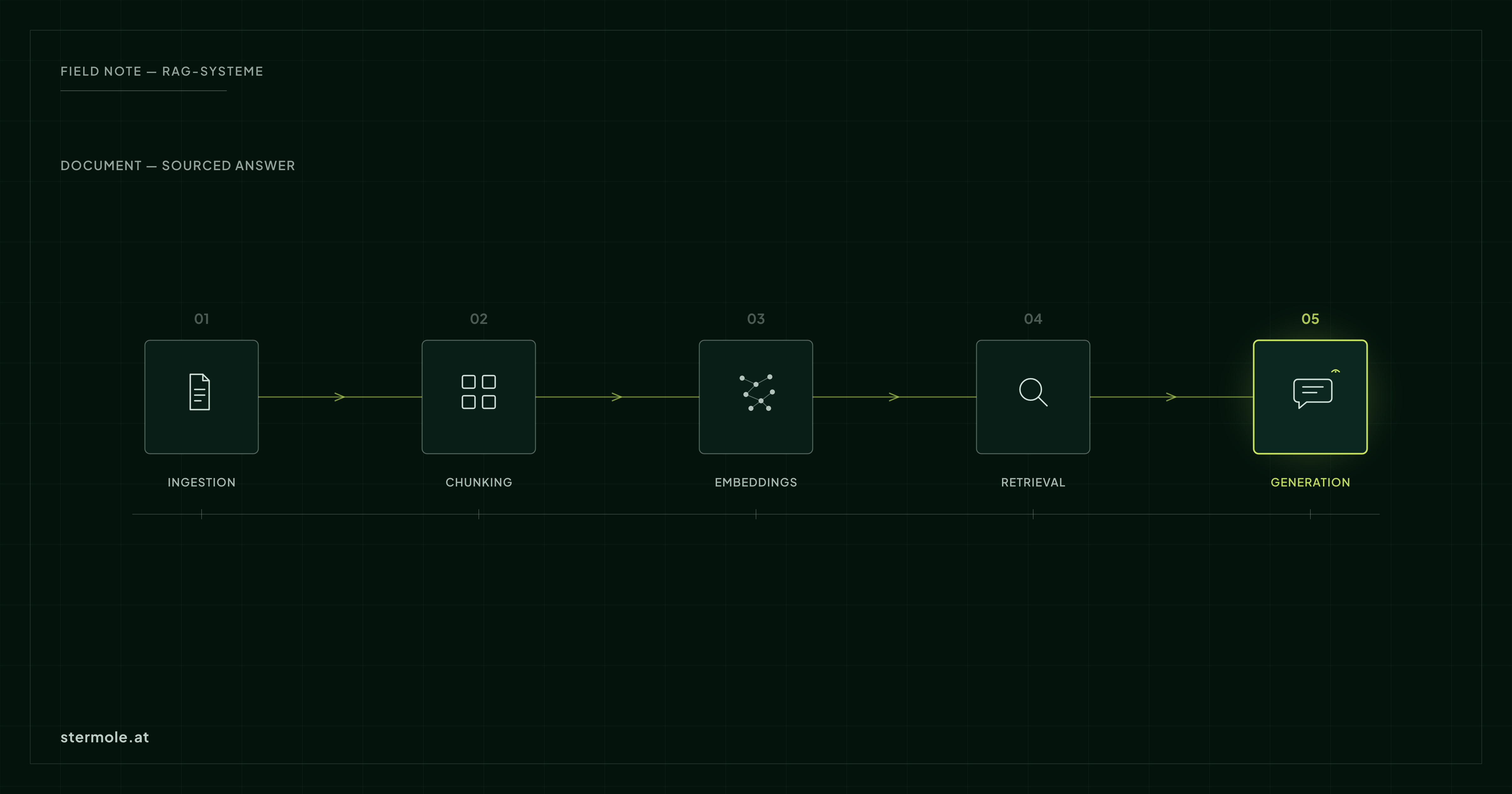
Retrieval-augmented generation (RAG) has become the standard pattern whenever AI needs to access internal knowledge: instead of retraining the model, you pull in relevant content at runtime. The concept is simple — but quality is decided in the details.
The chain is only as strong as its weakest link
A RAG system is a pipeline. Every step can ruin the result:
- Ingestion — read documents cleanly (PDF, Office, wiki). Bad parsing means bad answers.
- Chunking — meaningful sections instead of arbitrary cuts. Context has to be preserved.
- Embeddings — a model that fits the language and the domain.
- Retrieval — find relevant matches, often hybrid (semantic + keyword).
- Generation — the LLM answers only on the basis of the matches, with source attribution.
Most "RAG hallucinations" are not model errors but retrieval errors: the model was simply handed the wrong context.
Sovereignty is an architecture decision
With internal knowledge in particular, data ownership matters. The good news: RAG can be run in a fully sovereign way.
- Local or EU-hosted models for embeddings and generation.
- Clear separation of permissions — who is even allowed to retrieve which documents?
- Traceability — every answer points to its sources.
This keeps sensitive knowledge under control without depending on public-cloud AI.
A pragmatic starting point
You don't have to build everything at once. A robust first step:
- Choose a clearly bounded knowledge area (e.g. policies, contracts).
- Measure quality: does the system answer real questions correctly and with a source?
- Only then expand — once value and control are proven.
RAG becomes valuable when it is reliable — not when it looks impressive. The path there runs through clean data, clear permissions and measurable quality.