Why AI projects rarely fail because of the model
When an AI initiative stalls inside a company, the model is the first suspect. "Maybe we need a bigger LLM." Yet in most of the projects I support, the problem lies elsewhere — in the surrounding context that rarely makes it onto a slide.
The real bottleneck is the environment
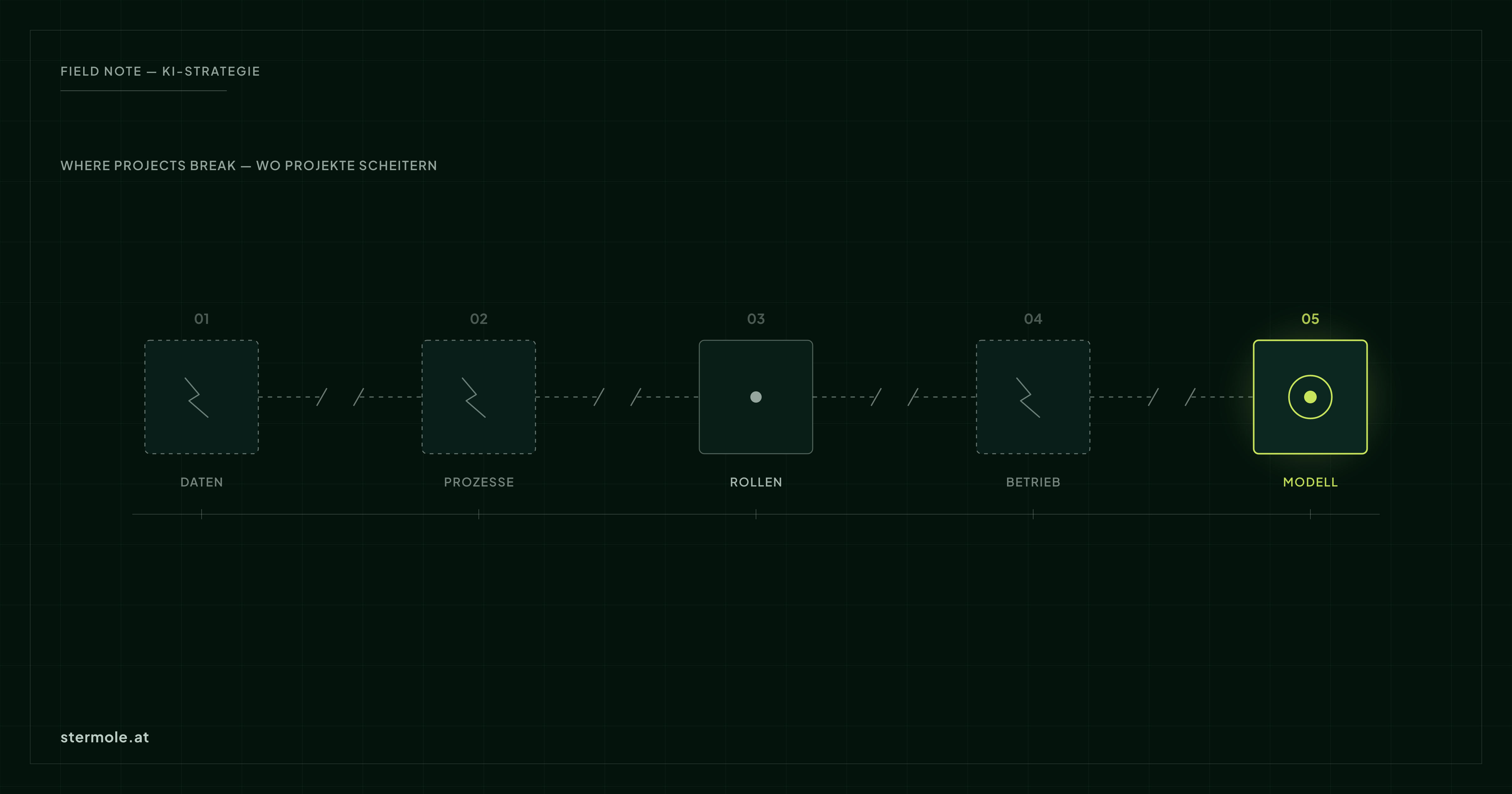
Modern models are remarkably capable. What they don't bring with them: clean data, clear processes, defined roles and an operating model that can carry the solution. That is exactly where the friction arises.
- Data is scattered, inconsistent and lacks clear access rules.
- Processes are implicit — nobody can say where the AI is actually supposed to plug in.
- Roles are unclear: who owns quality, data protection, maintenance?
- Operations are forgotten: a prototype is not a system that holds up day to day.
A demo proves that something is possible. A system proves that it is reliable. The real work lies in between.
Architecture before tool choice
The question "Which tool?" almost always comes too early. A more sensible order is:
- Clarify the value — which concrete problem are we solving, and for whom?
- Define the data and permission flow — what is allowed to go where, under which rules?
- Sketch the target architecture — local, EU-hosted or hybrid?
- Only then choose tooling — to fit the architecture, not the other way around.
Reverse this order and you build dependencies that are expensive to correct later.
What this means in practice
A realistic entry point is often not an AI programme but a clean workshop: prioritise the opportunities, name the risks, agree on a viable direction. That sounds unspectacular — but it saves exactly the correction loops that slow projects down later.
AI becomes valuable when it fits reality: into existing processes, systems and responsibilities. The model is rarely the hurdle.